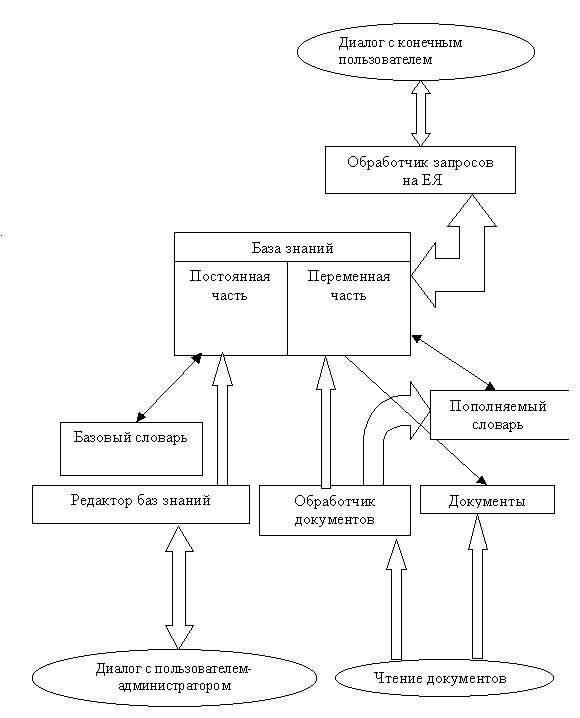
Архитектура программного обеспечения для поиска документов по запросу на естественном языке
А.В.Гаврилов
Новосибирский государственный технический университет, кафедра вычислительной техники, ул. Немировича-Данченко,
136, Новосибирск, Россия, 630087, email: avg@vt.cs.nstu.ru
ABSTRACT
The architecture of software for searching of semantics in documents is subscribed in this report. One is based on principle of semantics oriented analysis of natural language and use hierarchical semantic networks with elements of neural algorithms. The main algorithms of learning and searching are considered. Also the features of learning (creation of knowledge base) of proposed software are analyzed.
ВВЕДЕНИЕ.
Реализация диалога с компьютером на естественном языке (ЕЯ) является одной из главных проблем, решаемых в разделе информатики, называемой обычно “Искусственный интеллект”. Недаром тест Тьюринга, целью которого является оценка “качества” искусственной интеллектуальной системы, базируется на диалоге с компьютером.
Главной же проблемой при создании диалоговых систем с использованием ЕЯ является проблема распознавания смысла (семантики) предложений ЕЯ. Кроме того, решение этой проблемы актуально и для решения чисто прикладных задач, таких как
Решением проблемы формализации и распознавания смысла предложений на естественном языке занимаются давно с переменным успехом и зарубежные и отечественные исследователи [1-12].
Однако до сих пор нет достаточно полной модели представления знаний, содержащихся в предложении на ЕЯ, и эффективных принципов и алгоритмов обработки текстов на ЕЯ, объединяющих в себе достоинства методов инженерии знаний (например, семантических сетей) и преимущества нейронных сетей.
В статье делается попытка предложить такую модель и такие принципы и алгоритмы.
МОДЕЛЬ ЗНАНИЙ
В основе представления и распознавания смысла ЕЯ положены следующие основные принципы:
Первый их этих принципов (семантически-ориентированный анализ) был сформулирован и активно развивался в работах Нариньяни и Файна. Последние два принципа были сформулированы автором настоящей статьи и использованы им при создании системы программирования роботов на естественном языке [13-14].
На рисунке показана функциональная структура системы обработки запросов к документам по их содержанию.
База знаний
(БЗ) представляет собой семантическую сеть фреймов. Правда, фреймами узлы сети названы условно, т.к. они являются их вырожденным случаем и напоминают узлы семантической сетиУсловно в базе знаний можно выделить постоянную часть, описывающую предметную область, и переменную часть, описывающую содержимое документов.
Переменная часть формируется в результате обработки документов под управлением постоянной части.
С фреймом может ассоциироваться высказывание или набор высказываний с одинаковым смыслом, а также, слово из словаря или документ. Соответственно, одной из характеристик фрейма является его уровень в сети:
0 – фрейм, связанный непосредственно со словом или документом (фрейм-слово или фрейм-документ),
1 – фрейм, с которым ассоциируется словосочетание (составной фрейм),
2 – фрейм-понятие, включающее в себя ссылки на нескольких других фреймов, играющих определенные роли в этом понятии,
3 – фрейм-рубрика, описывающий понятие, которое является “описанием” (ссылкой, классом)) всех понятий и документов, связанные с этой рубрикой,
Особая разновидность фреймов уровня 0 – фреймы для связи с процедурами, используемыми при анализе предложений ЕЯ. Такие фреймы содержат знак препинания или слово, которое обрабатывается особым образом (например, слово - “не”, а знаки препинания – тире, двоеточие, запятая, и точка с запятой).
Фрейм состоит из слотов. Каждый слот – это его имя и значение.
Значением слота является ссылка на другой фрейм, на слово в словаре или на документ.
Во фрейме существуют (но не все из них используются в конкретном фрейме) следующие слоты:
Кроме того, фрейм включает в себя следующие параметры:
В системе используется два словаря:
Кроме того, некоторые слова (назовем их специальными) из этих двух словарей могут быть связаны (отождествлены) с символами-разделителями (пробел, тире, запятая). Они заменяются на соответствующие знаки при предварительной обработке предложения. Это позволяет фильтровать ненужные с точки зрения анализа смысла (отождествляя их с пробелами) и структурировать длинные словосочетания и процесс их анализа путем замены таких слов как “и” или “или” на запятые, “это” или “равно” - на тире, “состоит” – на двоеточие и т.п.
АЛГОРИТМЫ
Обработка предложения в режиме обучения состоит из следующих этапов:
Процедура распознавания-порождения фреймов рекурсивно обрабатывает объект-предложение, заменяя словосочетания между знаками препинания на распознанные в базе знаний или вновь созданные фреймы. В конце обработки этой процедурой список фреймов в объекте-предложении включает только один или два фрейма (в последнем случае в предложении присутствовал хотя бы один знак препинания "-" или двоеточие).
Фрейм-понятие создается по атрибутам в распознанных словах (это возможно при наличии, троек “субъект”-“действие”-“объект” или “объект-действие-объект” (в последнем случае во фрейме-понятии первый объект объявляется субъектом) или пар “объект”-“свойство”, “объект-действие”.
Фрейм-понятие или составной фрейм создаются только, если соответствующий фрейм не найден в базе знаний (операции 6 и 7).
При окончании обработки в случае, если в предложении есть тире, происходит создание связей типа Equal между фреймами - двумя частями предложения
.Если тире в предложении нет, создается составной фрейм из всех фреймов предложения. Последний созданный или распознанный фрейм запоминается как контекст. Если предложение начинается с тире, фрейм, соответствующий ему (распознанный или созданный) связявается связью Equal с фреймом-контекстом.
При создании составного фрейма или фрейма-понятия создается фрейм-документ и связь типа equal между ним и созданным фреймом.
При обработке фрейма-действия со словом “не” происходит инверсия следующего за ним фрейма-слова или в случае, если “не” встретилось в начале предложения или сразу после тире, происходит инверсия соответствующего составного фрейма или фрейма-понятия.
Фрейм-рубрика должен задаваться перед обработкой документа.
Обработка предложения в режиме обработки запроса
состоит из следующих этапов:Фреймы-рубрики (уровня 3) планируется использовать для сокращения количества найденных фреймов. При этом выбираются для последующих операций только те фреймы, которые связаны через ссылку Parent с соответствующим фреймом-рубрикой, или у которых эта ссылка не определена. Фрейм-рубрика может задаваться в программе поиска в меню выбора рубрики или при нахождении соответствующего слова (словосочетания) в распознаваемом предложении-запросе.
ОБУЧЕНИЕ ПРОГРАММЫ СЕМАНТИЧЕСКОГО ПОИСКА
Рекомендуется обучать программу (создавать базу знаний) в следующей последовательности:
Этапы 1-3 необходимы для лучшей структуризации базы знаний и обеспечения достаточно большого процента распознаваемых понятий при обработке документов на этапе 4. Иначе, при обработке запроса программа часто будет не находить в запросе какого-либо известного ей понятия, выполнять поиск по словам, входящим в запрос.
После каждого этапа можно сохранять полученную базу знаний и для продолжения обучения загружать сохраненную ранее.
ЗАКЛЮЧЕНИЕ
В настоящее время разработана демонстрационная версия программного обеспечения, состоящая из двух программ:
Пример запроса
, который может обрабатываться разработанной системой поиска документов по смыслу.Запрос: “Разработчики экспертных систем”.
Возможные варианты содержимого документов, удовлетворяющих данному запросу.
Содержимое документа 1: “Наши разработки: … экспертная оболочка ESWin”
Содержание документа 2: “Наша фирма разработала советующую систему на основе базе знаний …”
Содержание документа 3: “Вы можете заказать у нас разработку экспертной системы для …”
Содержание документа 4: “Фирма занимается разработкой программного обеспечения….. Наши продукты - …..инструментальная экспертная система ESWin”
Содержание документа 5: “Наши продукты…. Программа экономического анализа D … знания о рынке представлены в виде семантической сети (или правил, фреймов и т.п.)….”.
Для того, чтобы система могла обрабатывать запрос, как описано выше, в режиме обучения ей достаточно встретить в документах или обработать в диалоге следующие предложения:
Демонстрационная версия разработана в среде Delphi 5, требует RAM не менее 64 Мб, скорость процессора не менее 300 Мгц и доступна для скачивания по адресу
http://insycom.da.ru (только программа поиска с демонстрационной базой знаний и документами). База знаний в ней хранится в текстовом виде и загружается целиком при запуске программы.Программное обеспечение было испытано на компьютере с процессором AMD K6-2 350 Мгц и RAM 64 Мб. При этом база знаний была создана на основе предварительного диалога из порядка 40 обучающих предложений, обработки документов (формате .txt):
Созданная БЗ на носителе занимала около 8Мб (в текстовом виде) и содержала 87513 фреймов и 14715 слов в пополняемом словаре. Обработка в режиме обучения всех этих документов на указанном компьютере заняла около часа времени.
Предварительные испытания показали, что предложенные принципы и алгоритмы позволили построить систему, осуществляющую поиск документов и их фрагментов в ответ на запрос на естественном языке с довольно не тривиальными результатами. В найденных фрагментах могли отсутствовать слова запроса. Причем качество ответов сильно зависит от качества обучающего материала на этапах 1, 2 и 3 (см. выше).
Результаты испытаний позволили наметить пути дальнейшего усовершенствования предложенной архитектуры:
Планируется использовать разработанную архитектуру при построении ПО для поддержки работы с документами.
ЛИТЕРАТУРА